[자바] ForkJoinPool
Fork-Join 패턴은 대규모 작업을 작은 단위로 분할(Fork)하여 병렬로 처리(Execute)한 후, 결과를 합치는(Join) 병렬 프로그래밍 패턴이다. 분할 정복 알고리즘의 멀티스레딩 패턴이라고 볼 수 있다.
자바는 Fork-Join 패턴을 구현하기 위한 Fork/Join 프레임워크를 제공한다.
Fork Join 프레임워크의 주요 클래스는 다음과 같다.
1. ForkJoinPool
병렬 작업을 처리할 수 있는 특수한 스레드 풀로 기본적으로 사용 가능한 프로세서 수 만큼 스레드를 생성한다.
ForkJoinTask를 실행하는 데 사용되며, 내부적으로 Work-Stealing 알고리즘을 사용해 효율적인 병렬 처리를 한다.
ForkJoinPool pool = new ForkJoinPool(); // 기본 스레드 수: 가용 프로세서 수
2. ForkJoinTask<V>
Fork/Join 프레임워크에서 작업 단위를 표현하는 추상 클래스로 해당 클래스를 직접 사용하지 않고, 이를 상속하는 RecursiveTask 또는 RecursiveAction을 구현해서 사용한다.
3. RecursiveTask<V>, RecursiveAction
RecursiveTask<V> - 결과를 반환하는 병렬 작업을 처리할 때 사용한다. 제네릭 타입 V 는 결과 타입을 의미한다.
RecursiveAction - 반환값이 없는 작업(void 작업)을 처리할 때 사용한다.
이 클래스들은 compute() 메서드를 재정의하여 작업 내용을 구현하며, 보통 일정한 임계값을 기준으로 작업 범위를 판단한다. 작업 크기가 작으면 직접 처리하고, 크면 둘로 나눠 각각 병렬로 처리해 효율을 높인다.
다음 예시 코드를 살펴보자
public class Test {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(); // ForkJoinPool 생성
long result = pool.invoke(new Task(List.of(1, 2, 3, 4, 5, 6))); // task를 스레드 풀에 전달하고 해당 풀에 있는 별도의 스레드에서 실행
System.out.println("Result: " + result);
pool.close();
}
public static class Task extends RecursiveTask<Integer> {
private final List<Integer> numbers;
private static final int THRESHOLD = 2;
public Task(List<Integer> numbers) {
this.numbers = numbers;
}
@Override
protected Integer compute() {
System.out.println("스레드 [" + Thread.currentThread().getName() + "] 작업 시작: " + numbers);
if (numbers.size() <= THRESHOLD) {
return numbers.stream()
.reduce(0, Integer::sum);
}
int mid = numbers.size() / 2;
Task left = new Task(numbers.subList(0, mid));
Task right = new Task(numbers.subList(mid, numbers.size()));
left.fork(); // 비동기 실행
int rightResult = right.compute(); // 동기 실행 (재귀)
int leftResult = left.join(); // 결과 합침
System.out.println("left " + leftResult + " + right " + rightResult);
return leftResult + rightResult;
}
}
}
// 스레드 [ForkJoinPool-1-worker-1] 작업 시작: [1, 2, 3, 4, 5, 6]
// 스레드 [ForkJoinPool-1-worker-2] 작업 시작: [1, 2, 3]
// 스레드 [ForkJoinPool-1-worker-1] 작업 시작: [4, 5, 6]
// 스레드 [ForkJoinPool-1-worker-2] 작업 시작: [2, 3]
// 스레드 [ForkJoinPool-1-worker-3] 작업 시작: [4]
// 스레드 [ForkJoinPool-1-worker-1] 작업 시작: [5, 6]
// 스레드 [ForkJoinPool-1-worker-4] 작업 시작: [1]
// left 4 + right 11
// left 1 + right 5
// left 6 + right 15
// Result: 21리스트가 임계값을 넘어간다면 작업을 둘로 분할하고, 좌측 작업은 비동기로 실행한다.
그리고 우측 작업은 현재 스레드가 직접 실행한 후 비동기로 맡긴 작업(왼쪽)이 끝날 때까지 기다렸다가 결과를 가져오고 이를 병합하여 최종 결과를 만들어 낸다.
이렇게 각 분할은 fork, compute로 나뉘어 병렬로 처리하고 결과가 join 되며 올라온다.

Work Stealing
Work stealing은 병렬 프로그래밍에서 작업 부하를 효율적으로 분산시키기 위한 스케줄링 기법으로, Fork/Join 프레임워크와 같은 병렬 처리 환경에서 중요한 역할을 한다.
기본 원리: 각 스레드는 자신의 작업 큐를 가지고 있다. 스레드가 자신의 큐에 작업이 없는 경우 다른 스레드의 큐에서 작업을 훔쳐와서 실행한다.
1. pool.invoke(Task) - ForkJoinPool에 작업을 요청하면 pool 내부에 있는 외부 작업 큐에 작업이 저장된다.
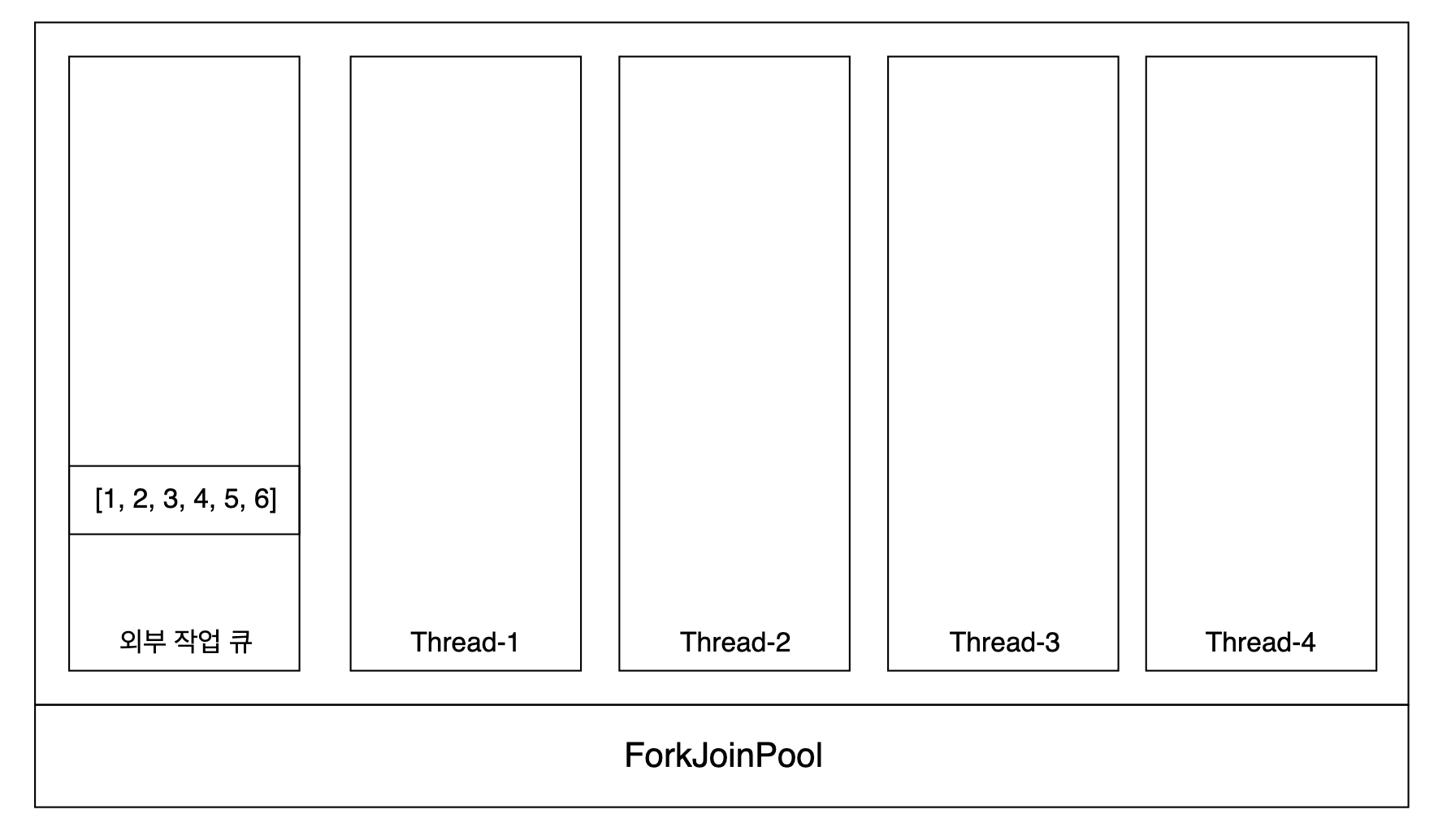
2. Thread1은 자신의 작업 큐에 작업이 없으므로 외부 작업 큐에서 자신의 큐로 작업을 가져온다.


4. 여기서 Thread-1 작업 큐에 있는 작업을 Thread-2가 훔쳐와서 자신의 작업 큐에 넣고 병렬적으로 실행한다.
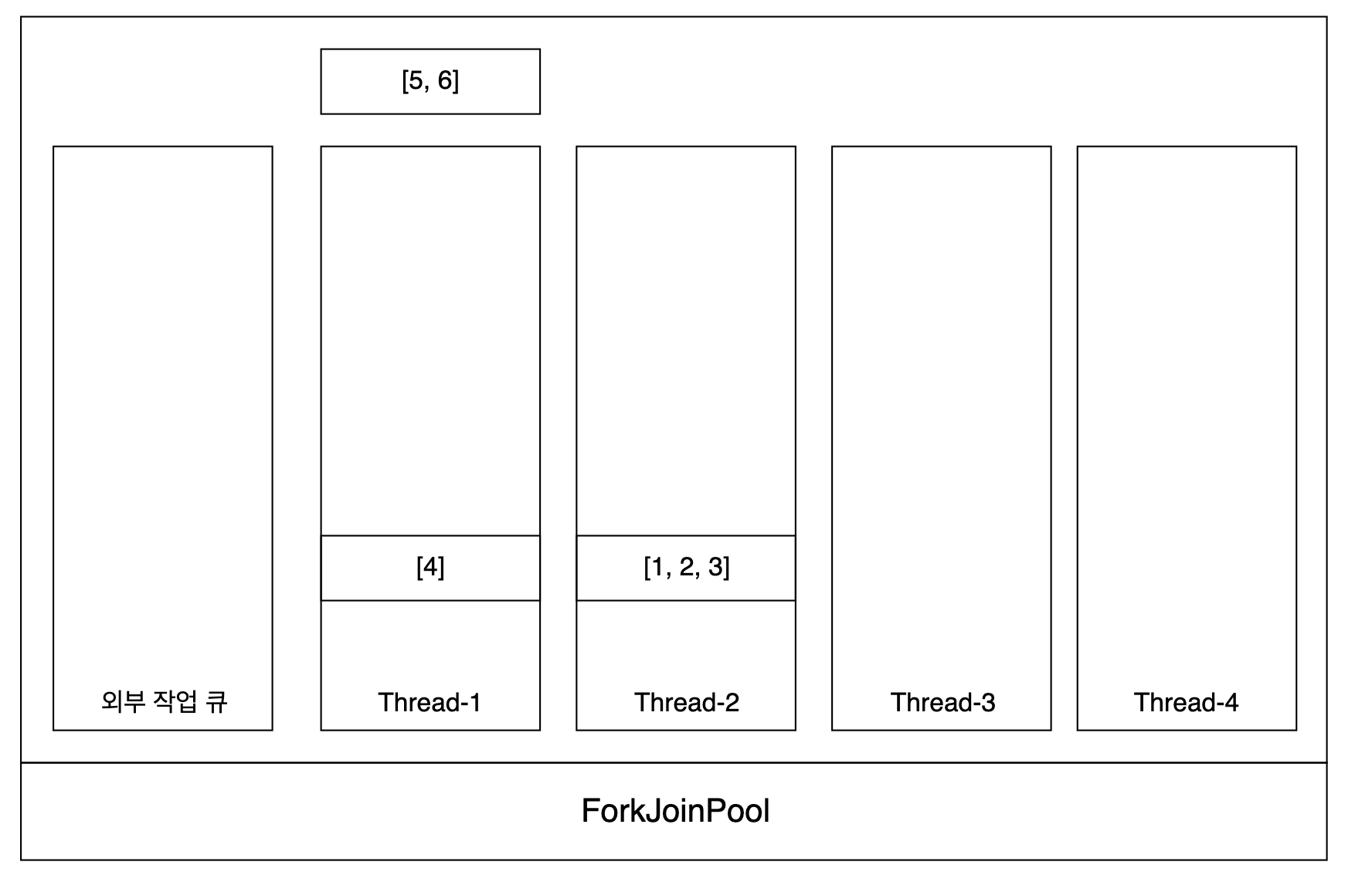
5. 마찬가지로 Thread-1 작업 큐에 있는 작업을 Thread-3이 훔쳐와서 자신의 작업 큐에 넣고 병렬적으로 실행한다.

6. 마지막으로 Thread-2 작업 큐에 있는 작업을 Thread-4가 훔쳐와서 자신의 작업 큐에 넣고 병렬적으로 실행한다.

이렇게 ForkJoinPool은 Work Stealing 기법을 통해 작업을 효율적으로 분산하여 처리하는 것이 가능해진다.
Common Pool
공용 풀은 Fork/Join 작업을 위해 자바8에서 부터 기본적으로 제공하는 스레드 풀이다.
공용 풀은 다음과 같은 특징이 있다.
1. 시스템 단위 공유: 별도의 ForkJoinPool을 생성하지 않고도 모든 애플리케이션에서 접근 가능한 공유 자원
2. 자동 관리: JVM에 의해 자동으로 생성되며 애플리케이션 종료 시 정리
3. 병렬 스트림 기반: Java 8의 병렬 스트림 작업은 기본적으로 이 공용풀을 사용
4. 크기 결정: 시스템의 가용 프로세서 수에 기반하여 생성되며, 기본적으로 (CPU 코어 수 - 1) 개의 스레드를 생성
위에서 살펴보았던 예제를 공용 풀을 사용하도록 변경하면 다음과 같다.
public class Test {
public static void main(String[] args) {
int processorCount = Runtime.getRuntime().availableProcessors();
ForkJoinPool commonPool = ForkJoinPool.commonPool();
System.out.println("가용 프로세서 수 : " + processorCount + " 스레드 개수 : " + commonPool.getParallelism());
Integer result = new Task(List.of(1, 2, 3, 4, 5, 6)).invoke();
System.out.println("Result: " + result);
}
public static class Task extends RecursiveTask<Integer> {
private final List<Integer> numbers;
private static final int THRESHOLD = 2;
public Task(List<Integer> numbers) {
this.numbers = numbers;
}
@Override
protected Integer compute() {
System.out.println("스레드 [" + Thread.currentThread().getName() + "] 작업 시작: " + numbers);
if (numbers.size() <= THRESHOLD) {
return numbers.stream()
.reduce(0, Integer::sum);
}
int mid = numbers.size() / 2;
Task left = new Task(numbers.subList(0, mid));
Task right = new Task(numbers.subList(mid, numbers.size()));
left.fork(); // 비동기 실행
int rightResult = right.compute(); // 동기 실행
int leftResult = left.join(); // 결과 합침
System.out.println("left " + leftResult + " + right " + rightResult);
return leftResult + rightResult;
}
}
}
// 가용 프로세서 수 : 11 스레드 개수 : 10
// 스레드 [main] 작업 시작: [1, 2, 3, 4, 5, 6]
// 스레드 [main] 작업 시작: [4, 5, 6]
// 스레드 [ForkJoinPool.commonPool-worker-1] 작업 시작: [1, 2, 3]
// 스레드 [main] 작업 시작: [5, 6]
// 스레드 [ForkJoinPool.commonPool-worker-2] 작업 시작: [1]
// 스레드 [ForkJoinPool.commonPool-worker-1] 작업 시작: [2, 3]
// 스레드 [ForkJoinPool.commonPool-worker-3] 작업 시작: [4]
// left 1 + right 5
// left 4 + right 11
// left 6 + right 15
// Result: 21
공용 풀은 ForkJoinPool.commonPool()을 통해 생성할 수 있다.
그리고 풀에다가 작업을 전달했던 이전 방법과는 다르게 여기서는 task.invoke()로 작업을 호출한다.
이렇게 하면 풀을 사용하지 않는 것처럼 보이지만, 현재 작업만 메인 스레드에서 시작하고 내부에서 fork()로 분할 후에는 공용 풀의 스레드가 분할된 작업을 처리한다.