스레드를 직접 생성해서 사용하면 다음과 같은 문제가 있다.
- 스레드 생성 시간으로 인한 성능 저하
- 스레드를 생성하는 작업은 커널 수준에서 시스템 콜에 의해 처리 → CPU 메모리와 리소스 사용
- 스레드는 독립적인 스택 영역을 가짐 → 메모리 소모
- 스레드의 관리가 어려움
- CPU, 메모리 자원이 한정적이므로 스레드는 무한하게 생성될 수 없음 + 인터럽트를 이용해 스레드를 급하게 종료해야 하거나 남은 스레드 작업을 확인해야하는 상황 → 스레드 관리가 필요함
- Runnable 인터페이스의 불편함
- Runnable 인터페이스는 반환 값 X, 체크 예외를 던질 수 없어 메서드 내부에서 예외 처리가 필요
위의 1, 2번 문제를 해결하기 위해 스레드를 생성하고 관리하는 풀이 필요한데 이를 스레드 풀이라고 한다.
스레드 풀
스레드 풀이란 말 그대로 스레드들을 관리하는 공간이라고 생각하면 된다.
스레드 풀 내부에 다음과 같이 스레드의 상한을 지정해놓고 만들어두면 작업이 들어올 때 풀 내부에서 쉬고 있는 스레드들이 작업을 처리한다.
작업이 처리된 뒤에는 다시 스레드 풀에 반납하여 해당 스레드는 재사용될 수 있다.

이로 인해 스레드의 생성 시간으로 인한 성능 저하 문제를 해결하고, 풀 내부에서 스레드들을 관리하므로 관리에 용이해진다.
자바는 이러한 스레드 풀과 관리, 그리고 아직 해결하지 못한 Runnable 인터페이스의 불편함을 해결하기 위해 Executor 프레임워크를 지원한다.
Executor
Executor 프레임워크는 위에서 말한 스레드 풀 사용과 관리를 도와주며 멀티스레딩을 쉽게 사용하도록 다양한 기능을 제공한다.
Executor 프레임워크의 주요 인터페이스
- Executor → void execute(Runnable command) 메서드 하나를 지니고 있는 실행 인터페이스.
- ExecutorService → 위 인터페이스를 확장하여 여러 기능을 제공하며 주로 해당 인터페이스를 사용한다.
- 기본적인 구현체는 ThreadPoolExecutor가 있다.
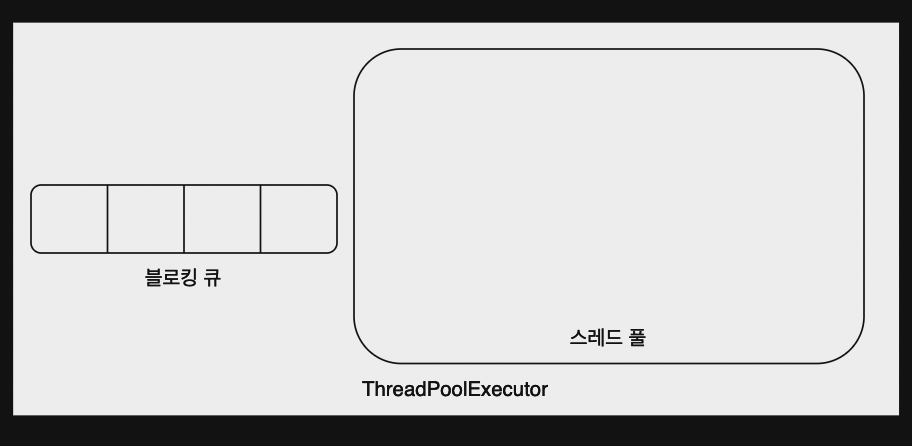
다음 코드를 통해 ThreadPoolExecutor에 대해 알아보자.
public class Test {
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(2, 2, 0,
TimeUnit.MICROSECONDS, new LinkedBlockingDeque<>());
System.out.println("== 작업 수행 전 Executor 상태 ==");
print(es);
es.execute(new MyRunnable("작업1"));
es.execute(new MyRunnable("작업2"));
es.execute(new MyRunnable("작업3"));
System.out.println("== 작업 수행 중 Executor 상태 ==");
print(es);
Thread.sleep(5000);
System.out.println("== 작업 완료 후 Executor 상태 ==");
print(es);
System.out.println("== 자원 정리 후 Executor 상태 ==");
es.close();
print(es);
}
private static void print(ExecutorService es) {
if (es instanceof ThreadPoolExecutor pool) {
System.out.println("스레드 풀에서 관리 중인 스레드 수 = " + pool.getPoolSize());
System.out.println("스레드 풀에서 작업을 수행 중인 스레드 수 = " + pool.getActiveCount());
System.out.println("큐 내부에서 대기 중인 작업 수 = " + pool.getQueue().size());
System.out.println("완료된 작업의 수 = " + pool.getCompletedTaskCount());
}
}
static class MyRunnable implements Runnable {
private final String taskName;
public MyRunnable(String taskName) {
this.taskName = taskName;
}
@Override
public void run() {
System.out.println(taskName + " 작업 시작");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println("인터럽트 발생!");
}
System.out.println(taskName + " 작업 완료");
}
}
}출력 결과는 위 코드를 설명하면서 적도록 하겠다.
먼저 ThreadPoolExecutor는 다음과 같이 생성된다.
new ThreadPoolExecutor(풀에서 관리되는 기본 스레드 수, 풀에서 관리되는 최대 스레드 수, 기본 스레드를 개수를 초과한 스레드들의 생존 시간으로 해당 시간 내에 작업 처리를 안하면 사라짐, 3번째 인자의 시간 단위, 작업을 보관할 블로킹 큐)
ExecutorService es = new ThreadPoolExecutor(2, 2, 0, TimeUnit.*MICROSECONDS*, new LinkedBlockingDeque<>());
해당 코드는 기본 2개, 최대 2개, 기본=최대 스레드 개수가 같으므로 생존 시간 지정 X, 크기가 무한인 블로킹 큐를 이용해서 ThreadPoolExecutor를 생성한 것!
이후 첫 출력을 확인해보자.
== 작업 수행 전 Executor 상태 ==
스레드 풀에서 관리 중인 스레드 수 = 0
스레드 풀에서 작업을 수행 중인 스레드 수 = 0
큐 내부에서 대기 중인 작업 수 = 0
완료된 작업의 수 = 0위에서 기본 스레드를 2개로 했는데 출력에는 현재 ThreadPoolExecutor의 스레드 개수가 0이다.
이는 ThreadPoolExecutor은 생성 시점에 풀 내부에 스레드를 만들어두지 않기 때문이다.
→ execute()를 통해 작업이 들어오면 스레드를 생성하고 이를 재사용함
→ 기본 2개이므로 2개 이상 작업이 들어와야 풀 내부에 2개를 생성하고 재사용. 즉 1개의 작업만 들어왔다면 풀 내부에 스레드는 1개만 생성
== 작업 수행 중 Executor 상태 ==
스레드 풀에서 관리 중인 스레드 수 = 2
스레드 풀에서 작업을 수행 중인 스레드 수 = 2
큐 내부에서 대기 중인 작업 수 = 1
완료된 작업의 수 = 0
작업1 작업 시작
작업2 작업 시작
작업2 작업 완료
작업1 작업 완료
작업3 작업 시작
작업3 작업 완료이후 3개의 작업을 execute(Runnable runnable)을 통해 수행한다.
위 결과를 보면 스레드가 2개 생성되었고 이 2개의 스레드가 작업을 수행 중. 작업을 받지 못한 스레드는 큐 내부에서 대기하고 있음을 확인할 수 있다.
해당 작업은 Runnable.run() 내부 구현을 보면 1초마다 진행된다.
== 작업 완료 후 Executor 상태 ==
스레드 풀에서 관리 중인 스레드 수 = 2
스레드 풀에서 작업을 수행 중인 스레드 수 = 0
큐 내부에서 대기 중인 작업 수 = 0
완료된 작업의 수 = 35초를 대기하게 되면 해당 작업들은 모두 완료가 된다. 여기서 기본 스레드 2개는 작업이 완료된 후에도 남아있는 것을 확인할 수 있다.
→ 해당 스레드는 풀 내부에서 관리되고 재사용
== 자원 정리 후 Executor 상태 ==
스레드 풀에서 관리 중인 스레드 수 = 0
스레드 풀에서 작업을 수행 중인 스레드 수 = 0
큐 내부에서 대기 중인 작업 수 = 0
완료된 작업의 수 = 3close()를 호출하면 풀 내부의 스레드들이 모두 사라진 것을 확인할 수 있다.
→ 자원을 정리
스레드 풀 내부의 스레드들은 WAITING 상태로 있다가 작업이 들어오면 RUNNABLE 상태가 되는 것!
Callable
처음 부분에서 Runnable의 불편함에 대해서 말을 했다.
→ Runnable 인터페이스는 반환 값 X, 체크 예외를 던질 수 없어 메서드 내부에서 예외 처리가 필요
이러한 문제를 해결하기 위해 Executor 프레임워크는 Callable 인터페이스를 지원한다.
public interface Callable<V> {
V call() throws Exception;
}Callable 인터페이스를 보면 call() 메서드에서 가장 상위 예외인 Exception을 던지므로 이를 구현하는 구현체에서 체크 예외를 던질 수 있으며 제네릭으로 타입을 받고 이를 반환 값으로 사용하는 것을 확인할 수 있다.
사용법은 Runnable과 같다. 위에서 static class로 구현했던 MyRunnable을 callable로 바꾸어 보겠다.
static class MyCallable<T> implements Callable<T> {
private final T taskName;
public MyCallable(T taskName) {
this.taskName = taskName;
}
@Override
public T call() throws InterruptedException {
System.out.println(taskName + " 작업 시작");
Thread.sleep(1000);
System.out.println(taskName + " 작업 완료");
return taskName;
}
}다음과 같이 수정이 가능하다. 당장은 반환 값을 이용한 작업을 하지는 않으므로 일단은 taskName을 반환하도록 하였다.
이렇게 반환 값이 필요한 작업을 할 때 runnable.get인스턴스변수()로 접근하여 값을 가져오는 것이 아닌 직접 반환이 가능하며 예외를 메서드에서 던질 수 있어 코드가 간결해진 것을 확인할 수 있다.
이렇게 바꾼 Callable은 다음과 같이 실행하면 된다.
Future<String> future1 = es.submit(new MyCallable<>("작업1"));
Future<String> future2 = es.submit(new MyCallable<>("작업2"));
Future<String> future3 = es.submit(new MyCallable<>("작업3"));
System.out.println("== 작업 수행 중 Executor 상태 ==");
System.out.println(future1);
System.out.println(future2);
System.out.println(future3);
print(es);execute가 아닌 callable을 인자로 받는 submit 메서드를 사용하면 된다.
이렇게 하면 위와 마찬가지로 실행된다.
근데 여기서 분명 우리는 String 타입의 제네릭 타입인자를 주었는데 반환은 Future 객체에 담겨서 반환되는 것을 확인할 수 있다.
그리고 이를 출력하면 다음과 같이 나온다.
java.util.concurrent.FutureTask@87aac27[Not completed, task = thread.executor.my.CallableTest$MyCallable@816f27d]
java.util.concurrent.FutureTask@6ce253f1[Not completed, task = thread.executor.my.CallableTest$MyCallable@3e3abc88]
java.util.concurrent.FutureTask@e9e54c2[Not completed, task = thread.executor.my.CallableTest$MyCallable@53d8d10a]분명 taskName을 반환하였는데 이렇게 출력되는 결과는 무엇일까?
Future
Future란 미래라는 뜻으로 미래의 결과를 받을 수 있는 객체이다.
우리가 처음 코드를 보면 작업하는데 1초의 시간이 든다. 근데 반환된 시점을 확인하면 아직 작업 수행 중인 상태이다.
즉 1초의 시간 동안 작업을 한 후 taskName을 반환해야 하는데 아직 작업이 완료되지 않은 시점임에도 불구하고 결과를 반환받을 수 있었다.
→ 작업들은 스레드 풀의 스레드가 실행하는데 해당 스레드가 언제 작업을 마치고 결과를 반환하는지 알 수 없다.
따라서 Future라는 객체를 통해 전달한 작업의 미래 결과를 확인할 수 있다.
future를 좀 더 확인해보기 위해 위 코드를 살짝 수정해보겠다.
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(1, 1, 0,
TimeUnit.MICROSECONDS, new LinkedBlockingDeque<>());
System.out.println("== 작업 수행 전 Executor 상태 ==");
print(es);
Future<String> future1 = es.submit(new MyCallable<>("작업1"));
Future<String> future2 = es.submit(new MyCallable<>("작업2"));
System.out.println("== 작업 수행 중 Executor 상태 ==");
System.out.println(future1);
System.out.println(future2);
print(es);
Thread.sleep(5000);
System.out.println("== 작업 완료 후 Executor 상태 ==");
System.out.println(future1);
System.out.println(future2);
print(es);
System.out.println("== 자원 정리 후 Executor 상태 ==");
es.close();
print(es);
}출력의 간소화를 위해 스레드 개수를 1개만 설정하고 작업이 수행 중일 때 Future 객체와 완료되었을 때 Future 객체를 살펴보도록 하겠다.
- 작업 수행 중
- FutureTask 내부에는 작업 완료 여부와 작업의 결과 값, 작업의 인스턴스를 가진다.
- submit()을 호출한 순간 작업이 바로 ThreadPoolExecutor 내부의 블로킹 큐에 들어가는 것이 아니라 해당 작업이 담긴 Future 객체를 생성 후 이를 블로킹 큐에 넣고 반환
- 결과로 반환되는 Future는 인터페이스 → 실제 전달되는 구현체는 FutureTask
== 작업 수행 중 Executor 상태 ==
java.util.concurrent.FutureTask@816f27d[Not completed, task = thread.executor.my.CallableTest$MyCallable@1218025c]
java.util.concurrent.FutureTask@3e3abc88[Not completed, task = thread.executor.my.CallableTest$MyCallable@87aac27]결과를 보면 FutureTask가 반환되었고, 작업은 Not completed 상태. 진행 중인 작업은 new Callable<>()로 생성한 thread.executor.my.CallableTest$MyCallable 타입의 인스턴스임을 확인할 수 있다.
- 작업 완료
== 작업 완료 후 Executor 상태 ==
java.util.concurrent.FutureTask@816f27d[Completed normally]
java.util.concurrent.FutureTask@3e3abc88[Completed normally]해당 작업이 완료 되었음을 확인할 수 있다.
그렇다면 call()에서 반환한 taskName은 어디에 있는걸까?
Future에서 get() 메서드를 통해 반환 값을 받을 수 있다. String taskName = future1.get();
위에서 Future 객체는 수행 중, 수행 완료 상태에 따라 결과가 다르게 반환되는 것을 확인할 수 있다.
작업이 완료되었으면 future.get()을 통해 받아올 수 있지만 완료되기 전이라면 어떻게 될까?
- 작업 수행 중
long startTime = System.currentTimeMillis();
Future<String> future1 = es.submit(new MyCallable<>("작업1"));
Future<String> future2 = es.submit(new MyCallable<>("작업2"));
System.out.println("== 작업 수행 중 Executor 상태 ==");
System.out.println("taskName = " + future1.get());
System.out.println("taskName = " + future2.get());
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
System.out.println("총 소요 시간: " + duration + "ms");출력 결과
== 작업 수행 중 Executor 상태 ==
작업1 작업 시작
작업1 작업 완료
작업2 작업 시작
taskName = 작업1
작업2 작업 완료
taskName = 작업2
총 소요 시간: 2016ms
먼저 결론부터 말하면 수행 중인 Future 객체에 get()을 호출한다면 호출한 스레드는 작업이 완료될 때 까지 WAITING 상태로 바뀐다.
→ future.get()은 thread.join()과 같은 blocking 메서드임
작업이 완료되지 않은 상태에서 get() 호출 시 결과를 받기 위해 호출한 스레드(메인 스레드)는 대기하게 된다.
즉 스레드가 작업1을 처리하기 위해 1초 걸리고 완료된 후 결과를 얻고, 이어서 작업2의 결과를 얻기 위해 1초 더 기다리면서 2초가 걸리게 된다.
현재 스레드 풀의 스레드 최대 개수는 1개이므로 2초가 걸리는 것!
만약 2개로 늘린다면?
== 작업 수행 중 Executor 상태 ==
작업1 작업 시작
작업2 작업 시작
작업1 작업 완료
작업2 작업 완료
taskName = 작업1
taskName = 작업2
총 소요 시간: 1009ms시간이 1초 걸리는 것을 확인할 수 있음.
→ 작업1, 작업2가 스레드 풀에 있는 2개의 스레드에 의해 병렬적으로 처리되고 1초면 두 작업이 모두 완료되므로 결과를 반환받을 수 있다.
- 작업 완료
Thread.sleep(2000);
long startTime = System.currentTimeMillis();
System.out.println("== 작업 완료 후 Executor 상태 ==");
System.out.println(future1);
System.out.println(future2);
System.out.println(future1.get());
System.out.println(future2.get());
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
System.out.println("총 소요 시간: " + duration + "ms");출력 결과
== 작업 완료 후 Executor 상태 ==
java.util.concurrent.FutureTask@3e3abc88[Completed normally] java.util.concurrent.FutureTask@6ce253f1[Completed normally]
taskName = 작업1
taskName = 작업2
총 소요 시간: 1ms
작업이 완료된 상태에서 get()을 호출하면 바로 결과를 반환받을 수 있는 것을 확인하였다.
따라서 Callable을 사용하면 Runnable의 반환 값이 없다는 점과 체크 예외를 메서드 내에서 모두 처리해야 한다는 단점을 모두 해결할 수 있다.
또한 여러 작업을 동시에 처리하고 반환 값을 이용하는 경우 기존에는 작업 스레드들을 thread.join() 메서드를 통해 일일히 대기하는 코드를 작성해야 했는데 future.get()을 이용하면 이러한 코드들을 모두 생략할 수 있어 가독성이 좋아지고 직관적이라는 장점이 있다.
Future는 요청 스레드를 blocking 상태로 만들지 않으면서 필요한 작업을 병렬적으로 수행할 수 있게 한다.
하지만 아래의 경우처럼 사용한다면 작업 하나를 요청하고 blocking 상태로 되고, 다음 작업을 요청하는 식으로 되어 병렬적으로 처리될 수 있다는 장점을 살릴 수 없으니 조심하자!
// (1)
Future<String> future1 = es.submit(new MyCallable<>("작업1")); // 논 블로킹
System.out.println("taskName = " + future1.get()); // 블로킹, 1초 대기함
Future<String> future2 = es.submit(new MyCallable<>("작업2")); // 논 블로킹
System.out.println("taskName = " + future2.get()); // 블로킹, 1초 대기함
// (2)
String taskName1 = es.submit(new MyCallable<>("작업1")).get(); // 블로킹
String taskName2 = es.submit(new MyCallable<>("작업2")).get(); // 블로킹submit()으로 필요한 모든 작업을 요청한 뒤 get()으로 결과를 반환받을 것!
Future 인터페이스에는 다양한 메서드를 지원한다.
- boolean cancel(boolean mayInterruptIfRunning)
- mayInterruptIfRunning
- true → Future를 취소 상태로 변경, 작업이 실행 중이라면 interrupt()를 호출해서 작업을 중단
- false → 마찬가지로 취소 상태로 변경하는데 실행 중인 작업을 중단하지 않음 (인터럽트를 발생시키지 않음)
- 반환 값
- true → 성공적으로 취소
- false → 이미 완료된 작업이거나 취소할 수 없는 경우
- mayInterruptIfRunning
- State state()
- Future의 상태 반환(자바 19지원)
- RUNNING(작업 실행 중), SUCCESS(성공 완료), FAILED(실패 완료), CANCELLED(취소 완료)
- V get()
- 작업이 완료될 때 까지 대기, 완료 시에 결과 반환
- 예외 발생
- ExecutionException → 작업 계산 중 예외가 발생했을 때
- InterruptedException → 대기 중 현재 스레드가 인터럽트 되었을 때
- 예외 발생
- 작업이 완료될 때 까지 대기, 완료 시에 결과 반환
- V get(long timeout, TimeUnit unit)
- get()과 동일하지만 시간 초과 시 예외 발생
- 예외 발생
- ExecutionException → 작업 계산 중 예외가 발생했을 때
- TimeoutException : 주어진 시간 내에 작업이 완료되지 않았을 때
- InterruptedException → 대기 중 현재 스레드가 인터럽트 되었을 때
- get()과 동일하지만 시간 초과 시 예외 발생
ExecutorService의 기능
위에서 우리는 ExecutorService에서 submit(), close()를 사용해보았는데 이 외에도 다양한 기능을 지원한다.
1. 컬렉션 처리 기능
우리는 지금까지 submit()을 이용해 단일 작업을 제출하였는데 ExecutorService는 작업을 컬렉션으로 처리할 수도 있다.
- invokeAll() : 모든 Callable 작업을 제출, 모든 작업이 완료될 때까지 기다림.
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService es = new ThreadPoolExecutor(3, 3, 0,
TimeUnit.MICROSECONDS, new LinkedBlockingDeque<>());
System.out.println("== 작업 수행 전 Executor 상태 ==");
print(es);
MyCallable<String> task1 = new MyCallable<>("작업1");
MyCallable<String> task2 = new MyCallable<>("작업2");
MyCallable<String> task3 = new MyCallable<>("작업3");
List<MyCallable<String>> tasks = List.of(task1, task2, task3);
List<Future<String>> futures = es.invokeAll(tasks);
System.out.println("== 작업 수행 중 Executor 상태 ==");
print(es);
Thread.sleep(1000);
for (Future<String> future : futures) {
System.out.println("taskName = " + future.get());
}
System.out.println("== 작업 완료 후 Executor 상태 ==");
print(es);
System.out.println("== 자원 정리 후 Executor 상태 ==");
es.close();
print(es);
}- invokeAny(): 가장 먼저 완료된 작업의 결과를 반환하고 나머지 작업은 취소.
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService es = new ThreadPoolExecutor(3, 3, 0,
TimeUnit.MICROSECONDS, new LinkedBlockingDeque<>());
System.out.println("== 작업 수행 전 Executor 상태 ==");
print(es);
MyCallable<String> task1 = new MyCallable<>("작업1");
MyCallable<String> task2 = new MyCallable<>("작업2");
MyCallable<String> task3 = new MyCallable<>("작업3");
List<MyCallable<String>> tasks = List.of(task1, task2, task3);
System.out.println("== 작업 수행 중 Executor 상태 ==");
print(es);
long start = System.currentTimeMillis();
Thread.sleep(1000);
System.out.println("== 작업 완료 후 Executor 상태 ==");
String taskName = es.invokeAny(tasks);
System.out.println("먼저 완료된 taskName = " + taskName);
print(es);
long end = System.currentTimeMillis();
System.out.println(end - start + "ms");
System.out.println("== 자원 정리 후 Executor 상태 ==");
es.close();
print(es);
}여기서 걸린 시간을 출력해보면 2초가 나온다. (sleep 1초 + 작업 수행 1초)
→ invokeAll(), invokeAny()는 블로킹 메서드임
→ invokeAll()의 반환값 List<Future>에서 get()을 호출하지 않아도 블로킹. 즉 결과를 get()으로 받아올 때는 이미 완료된 상태라 바로 받아올 수 있음.
2. 종료 기능
- shutdown()
- 새로운 작업을 받지 않으며, 이미 제출된 작업(작업 중인 작업과 큐에 있는 작업)은 모두 완료하고 종료함. (non-blocking 메서드)
- shutdownNow()
- 인터럽트를 일으켜 실행 중인 작업을 중단하고 대기 중인 작업은 반환하며 즉시 종료함. (non-blocking 메서드)
- isShutdown()
- ExecutorService가 종료되었는지 확인
- isTerminated()
- shutdown(), shutdownNow() 호출 후 모든 작업이 완료되었는지 확인
- awaitTermination(long timeout, TimeUnit unit)
- ExecutorService 종료 시 모든 작업이 완료될 때 까지 대기하는데, 지정 시간 동안만 대기. (blocking 메서드)
- close()
- 자바19부터 지원하는 종료 메서드로 shutdown() 호출하고 하루를 기다려도 작업이 완료되지 않으면 shutdownNow() 호출
- 호출한 스레드에 인터럽트가 발생 시에도 shutdownNow() 호출
3. 스레드 풀 관리 기능
위에서 ThreadPoolExecutor는 다음과 같이 생성된다고 하였다.
new ThreadPoolExecutor(풀에서 관리되는 기본 스레드 수, 풀에서 관리되는 최대 스레드 수, 기본 스레드를 개수를 초과한 스레드들의 생존 시간으로 해당 시간 내에 작업 처리를 안하면 사라짐, 3번째 인자의 시간 단위, 작업을 보관할 블로킹 큐)
처음에 예시에선 이해를 위해 기본 스레드 수와 최대 스레드 수를 같게 설정하였는데 이번엔 다르게 사용하여 최대 스레드 수가 어떤 의미인지 알아보도록 하겠다.
public class PoolSizeMainV1 {
public static void main(String[] args) {
ArrayBlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2);
ExecutorService es = new ThreadPoolExecutor(2, 4,
3000, TimeUnit.MILLISECONDS, workQueue);
print(es);
es.execute(new MyRunnable("작업1", 1000));
print(es);
es.execute(new MyRunnable("작업2", 1000));
print(es);
es.execute(new MyRunnable("작업3", 1000));
print(es);
es.execute(new MyRunnable("작업4", 1000));
print(es);
es.execute(new MyRunnable("작업5", 1000));
print(es);
es.execute(new MyRunnable("작업6", 1000));
print(es);
try {
es.execute(new MyRunnable("작업7", 1000));
} catch (RejectedExecutionException e) {
System.out.println("작업7 실행 거절 - 예외 발생 : " + e);
}
sleep(3000);
log("== 작업 수행 완료 ==");
print(es);
sleep(3000);
log("== maximumPoolSize 대기 시간 초과 ==");
print(es);
es.close();
log("== shutdown 완료 ==");
print(es);
}
private static void print(ExecutorService es) {
if (es instanceof ThreadPoolExecutor pool) {
System.out.println("[pool = " + pool.getPoolSize() +
", active = " + pool.getActiveCount() +
", queuedTask = " + pool.getQueue().size() +
", completedTask = " + pool.getCompletedTaskCount() + "]");
}
}
private static void sleep(long sleepMs) {
try {
Thread.sleep(sleepMs);
} catch (InterruptedException e) {
log("인터럽트 발생, " + e.getMessage());
throw new RuntimeException(e);
}
}
static class MyRunnable implements Runnable {
private final String taskName;
private final long sleepMs;
public MyRunnable(String taskName, long sleepMs) {
this.taskName = taskName;
this.sleepMs = sleepMs;
}
@Override
public void run() {
System.out.println(taskName + " 작업 시작");
try {
Thread.sleep(sleepMs);
} catch (InterruptedException e) {
System.out.println("인터럽트 발생, " + e.getMessage());
throw new RuntimeException(e);
}
System.out.println(taskName + " 작업 완료");
}
}
}[pool = 0, active = 0, queuedTask = 0, completedTask = 0]
[pool = 1, active = 1, queuedTask = 0, completedTask = 0]
[pool = 2, active = 2, queuedTask = 0, completedTask = 0]
[pool = 2, active = 2, queuedTask = 1, completedTask = 0]
[pool = 2, active = 2, queuedTask = 2, completedTask = 0]
작업1 작업 시작
작업2 작업 시작
[pool = 3, active = 3, queuedTask = 2, completedTask = 0]
작업5 작업 시작
작업6 작업 시작
[pool = 4, active = 4, queuedTask = 2, completedTask = 0]
작업7 실행 거절 - 예외 발생 : java.util.concurrent.RejectedExecutionException: Task thread.executor.my.PoolSizeMainV1$MyRunnable@404b9385 rejected from java.util.concurrent.ThreadPoolExecutor@3a71f4dd[Running, pool size = 4, active threads = 4, queued tasks = 2, completed tasks = 0]
작업5 작업 완료
작업2 작업 완료
작업1 작업 완료
작업6 작업 완료
작업4 작업 시작
작업3 작업 시작
작업3 작업 완료
작업4 작업 완료
== 작업 수행 완료 ==
[pool = 4, active = 0, queuedTask = 0, completedTask = 6]
== maximumPoolSize 대기 시간 초과 ==
[pool = 2, active = 0, queuedTask = 0, completedTask = 6]
== shutdown 완료 ==
[pool = 0, active = 0, queuedTask = 0, completedTask = 6]먼저 이번에는 ExecutorService를 기본 스레드 2개, 최대 스레드 4개, 초과된 스레드의 생존 시간 3초, 크기가 2인 블로킹 큐를 이용하여 ExecutorService를 만들었다.
- 먼저 ExecutorService 생성 직후 아무 작업을 수행하지 않았으므로 스레드 풀 내부는 비어 있음.
- 작업1 실행 → 스레드 풀에 스레드 1개 생성 후 작업 진행
- 작업2 실행 → 스레드 풀에 스레드 1개 생성 후 작업 진행
- [pool = 2, active = 2, queuedTask = 0, completedTask = 0]
- 작업3 실행 → 스레드가 늘어나지 않고 큐에 대기
- 작업4 실행 → 스레드가 늘어나지 않고 큐에 대기
- [pool = 2, active = 2, queuedTask = 2, completedTask = 0]
- 작업5 실행 → 큐가 가득찬 상태 (긴급 상황). 기본 스레드 개수를 넘어 스레드가 하나 늘어난 것을 확인할 수 있음. 그리고 이렇게 생긴 초과 스레드가 바로 작업5를 실행한다.
- 작업6 실행 → 큐가 가득찬 상태 (긴급 상황). 기본 스레드 개수를 넘어 스레드가 하나 늘어난 것을 확인할 수 있음. 그리고 이렇게 생긴 초과 스레드가 바로 작업6를 실행한다.
- [pool = 4, active = 4, queuedTask = 2, completedTask = 0]
- 작업7 실행 → 지정한 최대 스레드 4개를 넘어가자 RejectedExecutionException 을 발생시키며 작업을 거절
- 작업1, 2를 끝낸 스레드가 작업3, 4를 실행한다.
- sleep()으로 작업이 모두 완료될 때 까지 대기. 이 때 기본 스레드의 개수는 4개임
- [pool = 4, active = 0, queuedTask = 0, completedTask = 6]
- sleep(3000)으로 대기. 이는 ExecutorService에서 선언했던 초과 스레드의 생존 기간임.
- sleep()으로 인해 초과 스레드는 생존 기간 동안 작업을 하지 않음.
- 즉 초과되었던 스레드 2개가 사라져 기본 스레드의 개수가 처음에 선언했던 2개로 돌아왔음을 확인
- [pool = 2, active = 0, queuedTask = 0, completedTask = 6]
- shutdown() 호출 후 자원 정리
- [pool = 0, active = 0, queuedTask = 0, completedTask = 6]
즉 여기서 최대 스레드의 개수는 큐가 가득차서 더 이상 큐에 수용할 수 없는 상황에서 요청이 들어왔을 때 늘어나는 것을 확인했고 이 때 들어온 요청은 바로 초과 스레드가 처리하는 것을 알 수 있다.
또한 큐도 가득차고 최대 스레드 수 역시 더 이상 늘어날 수 없다면 작업을 거절한다.
4. 스레드 미리 생성 기능
지금까지 스레드를 생성할 때 작업이 없으면 ExecutorService에 스레드가 생성되지 않고 작업이 들어올 때 생성된 후 이것이 재사용 되었다.
응답이 매우 중요한 서버라면 미리 풀 내부에 스레드를 생성시켜야 하는데 ThreadPoolExecutor.prestartAllCoreThreads() 를 통해 기본 스레드들을 요청이 들어오기 전에 미리 풀 내부에 만들어서 재사용할 수 있다.
public class Test2 {
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(100);
System.out.println("prestartAllCoreThreads 실행 전");
print(es);
ThreadPoolExecutor poolExecutor = (ThreadPoolExecutor) es;
poolExecutor.prestartAllCoreThreads();
System.out.println("prestartAllCoreThreads 실행 후");
print(es);
es.close();
}
private static void print(ExecutorService es) {
if (es instanceof ThreadPoolExecutor pool) {
System.out.println("[pool = " + pool.getPoolSize() +
", active = " + pool.getActiveCount() +
", queuedTask = " + pool.getQueue().size() +
", completedTask = " + pool.getCompletedTaskCount() + "]");
}
}
}출력 결과
prestartAllCoreThreads 실행 전
[pool = 0, active = 0, queuedTask = 0, completedTask = 0]
prestartAllCoreThreads 실행 후
[pool = 100, active = 0, queuedTask = 0, completedTask = 0]
참고 : ExecutorService es = Executors.newFixedThreadPool(100) 고정 풀 전략으로 해당 코드는 아래와 같다.
밑에서 이게 무엇인지 좀 더 자세히 설명하겠다.
ExecutorService es = new ThreadPoolExecutor(100, 100, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());Graceful shutdown
시스템이나 애플리케이션을 중단할 때, 요청을 더 받지 않으며, 현재 진행 중인 작업은 안전하게 마무리하고, 리소스를 적절히 해제한 후 정상적으로 종료하는 것.
shutdown()을 호출해서 이미 들어온 작업을 모두 처리하고 서비스를 Graceful shutdown 하는 것이 이상적이지만 만약 큐에 엄청 많은 요청이 대기 중이거나 특정 작업 수행 중에 문제가 생겨 작업이 끝나지 않는 경우가 생긴다면 해당 메서드만으로는 부족할 수 있다.
따라서 보통은 Graceful shutdown 되도록 종료하는 시간을 정하고 이 시간 동안에 작업을 처리, 처리하지 못하면 문제가 있다고 가정하고 shutdownNow()를 호출하여 작업들을 강제 종료한다.
→ close() 메서드가 위와 같이 구현되어 있다. shutdown() 호출, 하루가 지나도 작업이 처리가 안되면 → shutdownNow() 호출하여 강제 종료
위에서 ExecutorService가 제공하는 종료 기능을 적절히 활용하여 Graceful shutdown을 구현해보자.
public class ExecutorShutdownTest {
public static void main(String[] args) {
ExecutorService es = Executors.newFixedThreadPool(2);
es.execute(new MyRunnable("작업1", 1000));
es.execute(new MyRunnable("작업2", 1000));
es.execute(new MyRunnable("작업3", 1000));
es.execute(new MyRunnable("작업4", 50000));
print(es);
System.out.println("== shutdown 시작 ==");
shutdownAndAwaitTermination(es);
System.out.println("== shutdown 완료 ==");
print(es);
}
private static void shutdownAndAwaitTermination(ExecutorService es) {
es.shutdown(); // 새로운 작업을 받지 않음. 처리 중이거나 큐에 이미 대기 중인 작업은 처리 후 종료.
try {
// 이미 대기 중인 작업들을 모두 완료할 때 까지 10초 대기
System.out.println("서비스 정상 종료 시도 중");
if(!es.awaitTermination(10, TimeUnit.SECONDS)){
// 위 시간 내에 처리가 안되면 문제가 있다고 판단
System.out.println("서비스 정상 종료 실패 -> 강제 종료 시도");
es.shutdownNow();
// 작업이 취소될 때 까지 대기
if (!es.awaitTermination(10, TimeUnit.SECONDS)) {
System.out.println("서비스가 종료되지 않았습니다.");
}
}
} catch (InterruptedException e) {
es.shutdownNow();
// throw new RuntimeException(e);
}
}
private static void print(ExecutorService es) {
if (es instanceof ThreadPoolExecutor pool) {
System.out.println("스레드 풀에서 관리 중인 스레드 수 = " + pool.getPoolSize());
System.out.println("스레드 풀에서 작업을 수행 중인 스레드 수 = " + pool.getActiveCount());
System.out.println("큐 내부에서 대기 중인 작업 수 = " + pool.getQueue().size());
System.out.println("완료된 작업의 수 = " + pool.getCompletedTaskCount());
}
}
static class MyRunnable implements Runnable {
private final String taskName;
private final long sleepMs;
public MyRunnable(String taskName, long sleepMs) {
this.taskName = taskName;
this.sleepMs = sleepMs;
}
@Override
public void run() {
System.out.println(taskName + " 작업 시작");
try {
Thread.sleep(sleepMs);
} catch (InterruptedException e) {
System.out.println("인터럽트 발생, " + e.getMessage());
throw new RuntimeException(e);
}
System.out.println(taskName + " 작업 완료");
}
}
}결과
작업1 작업 시작
작업2 작업 시작
스레드 풀에서 관리 중인 스레드 수 = 2
스레드 풀에서 작업을 수행 중인 스레드 수 = 2
큐 내부에서 대기 중인 작업 수 = 2
완료된 작업의 수 = 0
== shutdown 시작 ==
서비스 정상 종료 시도 중
작업1 작업 완료
작업3 작업 시작
작업2 작업 완료
작업4 작업 시작
작업3 작업 완료
서비스 정상 종료 실패 -> 강제 종료 시도
인터럽트 발생, sleep interrupted
== shutdown 완료 ==
스레드 풀에서 관리 중인 스레드 수 = 0
스레드 풀에서 작업을 수행 중인 스레드 수 = 0
큐 내부에서 대기 중인 작업 수 = 0
완료된 작업의 수 = 4
Exception in thread "pool-1-thread-2" java.lang.RuntimeException: java.lang.InterruptedException: sleep interrupted
at thread.executor.my.ExecutorShutdownTest$MyRunnable.run(ExecutorShutdownTest.java:62)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
at java.base/java.lang.Thread.run(Thread.java:1583)
Caused by: java.lang.InterruptedException: sleep interrupted
at java.base/java.lang.Thread.sleep0(Native Method)
at java.base/java.lang.Thread.sleep(Thread.java:509)
at thread.executor.my.ExecutorShutdownTest$MyRunnable.run(ExecutorShutdownTest.java:59)
... 3 more- shutdown() → 큐에 있거나 처리 중인 작업을 마저 끝내고 종료. 논 블로킹 메서드이므로 바로 다음 코드 호출
- if(!es.awaitTermination(10, TimeUnit.SECONDS)){ … } 호출하는데 이는 블로킹 메서드. 10초 간 대기하는데 모든 작업이 완료되면 true, 그렇지 않으면 false 반환
- 위 코드에선 작업4는 완료가 안되어 false를 반환함.
- es.shutdownNow() 를 호출하여 강제 종료 → 인터럽트 발생하면서 스레드 작업을 종료하고 강제 종료 완료
- if(!es.awaitTermination(10, TimeUnit.SECONDS)){ … } 를 한번 더 호출하는데 이는 인터럽트 호출 시에도 자원을 정리하는 등의 간단한 작업을 수행할 수도 있음. 이러한 이유로 종료되는데 걸리는 시간을 추가로 대기하는 것
- 근데 이 경우에서도 false가 나온다면 최악의 경우 인터럽트를 받을 수 없는 코드를 수행 중 일 수도 있으므로 로그를 남겨 확인해야 한다.
while(true) { empty } // 인터럽트를 받을 수 없음- 인터럽트는 Thread.sleep(), wait(), join()와 같은 블로킹 상태에 있을 때 받을 수 있음
- 즉 WAITING / TIMED_WAITING -> RUNNABLE 상태 변화를 일으키는데 위 코드는 대기 중이 아니고 무한 루프로 실행 중인 상태이므로 인터럽트를 못 받음
Executor 스레드 풀 관리 전략
- 단일 스레드 풀 전략 - Executors.newSingleThreadExecutor()
- 스레드 풀에 기본 스레드 1개만 사용하고 큐 사이즈에 제한이 없음. → 간단히 사용하거나 테스트 용
- 아래 코드와 동일
ExecutorService es = new ThreadPoolExecutor(
1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()
)- 고정 풀 전략 - Executors.newFixedThreadPool(nThreads)
- 스레드 풀에 인자로 넘긴 nThreads 만큼 기본 스레드를 생성하고 초과 스레드는 생성하지 않음.
- LinkedBlockingQueue 이므로 큐 사이즈에 제한이 없음.
- 스레드 수가 고정되어 있어 CPU, 메모리 리소스가 어느정도 예측 가능한 안정적인 방식.
- 아래 코드와 동일
ExecutorService es = new ThreadPoolExecutor(
nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()
);→ 해당 방식은 사용자가 늘어도 CPU, 메모리 사용량이 급증하지 않는다. (스레드 수가 고정되어 있으므로)
하지만 큐의 사이즈는 제한이 없어 사용자가 늘어나면 작업 처리 속도보다 요청이 들어오는 속도가 더 빨라 사용자 입장에서는 응답이 늦어진다는 문제가 발생할 수 있다.
즉 서버의 자원은 여유가 있는데 사용자 응답은 늦어지는 상황이 발생할 수 있음.
트래픽이 일정하고, 시스템 안전성이 중요한 경우에 적용
- 캐시 풀 전략 - Executors.newCachedThreadPool()
- SynchronousQueue는 BlockingQueue의 구현체 중 하나로 내부에 저장 공간이 없어 생산자가 직접 소비자에게 작업을 전달하는 큐.
- 큐의 크기 0, 생산자가 작업을 전달하면 소비자가 해당 작업을 꺼낼 때 까지 대기
- 소비자가 작업을 요청 시 대기 중인 생산자가 직접 전달하고 반환. 반대의 경우도 동일
- 아래 코드와 동일
- SynchronousQueue는 BlockingQueue의 구현체 중 하나로 내부에 저장 공간이 없어 생산자가 직접 소비자에게 작업을 전달하는 큐.
ExecutorService es = new ThreadPoolExecutor(
0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()
);→ 매우 빠르고 유연함. 이 방식은 기본 스레드가 없고, 큐에 작업이 쌓이지 않아 작업이 들어오면 즉시 초과 스레드가 생성되어 작업이 처리된다.
초과 스레드의 제한 역시 두지 않아 CPU, 메모리 자원을 최대로 활용할 수 있고, 초과 스레드의 생존 기간이 60초이기 때문에 작업 수에 맞게 스레드가 재사용된다.
즉 요청이 많아지면 초과 스레드가 많아지고, 요청이 줄어들면 다시 감소하여 유연하지만 서버가 감당할 수 있는 임계점을 넘어가면 시스템이 다운될 수 있다.
요청에 빠르게 대응해야 하는 일반적인 서비스에 적용
따라서 사용자는 CPU, 메모리 자원의 적정 수준을 찾아 요청을 처리하고, 요청이 폭증하면 처리 될 수 있는 수준의 요청만 처리하고 나머지는 거절해야 한다.
주의! → 해당 큐는 사이즈가 제한이 없는 큐로 다음과 같이 사용하면 초과 스레드가 생성될 수 없으므로 조심해야한다.
new ThreadPoolExecutor(100, 200, 60, TimeUnit.SECONDS, new LinkedBlockingQueue());Executor 예외 정책
위에서 시스템이 수용할 수 있는 요청을 넘어가면 어떻게 해야하는지 예외 정책이 필요한데 ThreadPoolExecutor는 다양한 예외 정책을 제공한다.
지금까지 ExecutorService를 선언할 때 new ThreadPoolExecutor(기본 스레드 수, 최대 스레드 수, 초과 스레드들의 생존 시간, 생존 시간 단위, 블로킹 큐) 방식으로 선언했다.
큐 다음 부분에 RejectedExecutionHandler 타입의 인자를 추가하여 예외 정책을 적용할 수 있다.
종류
- AbortPolicy - 기본 정책(생략 가능)으로 새로운 작업 제출 시 허용 작업을 초과하여 작업이 거절되면 RejectedExecutionException 발생
- RejectedExecutionException 예외를 잡아서 작업을 포기하거나, 사용자에게 알리거나, 다시 시도하는 등 필요한 코드 구현
ExecutorService es = new ThreadPoolExecutor(
2, 2, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(2), new ThreadPoolExecutor.AbortPolicy()
);- DiscardPolicy - 거절된 작업을 무시하고 아무런 예외도 발생 시키지 않음.
ExecutorService es = new ThreadPoolExecutor(
2, 2, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(2), new ThreadPoolExecutor.DiscardPolicy()
);- CallerRunsPolicy - 새로운 작업을 제출한 스레드가 대신해서 직접 작업을 실행.
- 생산자 스레드가 직접 작업을 소비하여 작업의 생산 속도가 느려짐. 생산 속도가 너무 빠르면 해당 정책으로 속도 조절 가능
ExecutorService es = new ThreadPoolExecutor(
2, 2, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(2), new ThreadPoolExecutor.CallerRunsPolicy()
);- 사용자 정의 - RejectedExecutionHandler을 개발자가 직접 정의하여 거절 정책을 사용 가능
참고
김영한의 실전 자바 - 고급 1편, 멀티스레드와 동시성 강의 | 김영한 - 인프런
김영한 | 멀티스레드와 동시성을 기초부터 실무 레벨까지 깊이있게 학습합니다., 국내 개발 분야 누적 수강생 1위, 제대로 만든 김영한의 실전 자바[사진][임베딩 영상]단순히 자바 문법을 안다?
www.inflearn.com
'JAVA' 카테고리의 다른 글
| [자바] 소켓 프로그래밍 (0) | 2024.12.25 |
|---|---|
| [자바] I/O 스트림 (0) | 2024.12.25 |
| [자바] 동시성 컬렉션 (0) | 2024.12.25 |
| [자바] 원자적 연산, 동기화 (0) | 2024.12.25 |
| [자바] Producer-Consumer Problem, BlockingQueue (0) | 2024.12.25 |


